CCF大赛做了两个多月终于结束了,最后能拿到第五的成绩很意外也很高兴,毕竟第一次参加这种高规格的数据挖掘大赛,自己收获了很多。
在听取完前几名,包括其他比赛的答辩后,发现现在真是一个深度学习的时代。不管是在图像文本和其他领域,深度学习都表现出了比传统方法好很多的效果。队友戏言,我们是在没有用深度学习的团队中做的最好的,也算是对我们的一点安慰。
在这里对自己的之前两个月的成果做一点总结和思考吧。鉴于队友的博客 传送门 对于我们的整体模型已经讲得差不多了。这里对其算是一个补充和自己的一点感受吧,尽量不让大家感觉重复。
1. 算法描述
本题目提供用户历史一个月的查询词与用户的人口属性标签(包括性别、年龄、学历)做为训练数据,要求参赛人员通过机器学习、数据挖掘技术构建分类算法来对新增用户的人口属性进行判定。其中性别是二分类问题,年龄和学历都是六分类问题。数据集复赛为10w条数据。
2. 整体流程概述
2.1 特征工程
2.1.1 分词
- 分词我们使用的是jieba分词包,从分词速度到精度都还不错。个人感觉想提高分词精度,一个好的自定义词典更加重要。
- 分词后处理部分,我们对停用词和单词的词性进行了过滤,只留下名词和动词。也是为了达到一种降维的目的吧。
- 最后的第一名大神考虑到了一点,他在分词时,保留了查询词条中的空格信息。他分析后认为博士词条空格数明显更多,是因为高学历者对于搜索引擎的使用更加熟练。这一点也得到了评委们的认可,在工业界的确也是这样处理的。
2.1.2 特征权重
文本分类的一个经典模型就是VSM模型。其中词-文档矩阵使用的特征权重就是TFIDF。我们在TFIDF中加入了类间差异信息,改进出了一个基于布尔模型的S-TFIWF算法。细节大家可以看这里 传送门 。
对于TFIDF的不足,在前几名中都没有对其进行改变。这算是我们的一点亮点。其实在国内外不少论文中,都有很多对于TFIDF的改进,所以大家在做文本分类的时候,也可以试着去使用一些改进的特征权重算法,或者使用我们的这个O(∩_∩)O~。
2.1.3 特征选择
这里是我们本次比赛中可以算是最为纠结的的一点。尝试了多种特征选择算法,但是最后发现还是利用单词出现频率出现效果最好,这一点我们很惆怅。本来想在决赛中看看其他队伍的特征选择情况。然而他们是选择了融入其他种类特征,或者直接走深度学习。几乎没有做特征选择。所以,还是深度学习大法好啊。
2.1.4 融入其他特征
在nlp领域,有两个很著名的特征:LDA和词向量(word2vec,doc2vec)。这两个特征同样可以表达出文本的特征信息,甚至比起TFIDF更好。详细的介绍大家可以百度一波。
在我们的使用中,我们是讲训练好的word2vec信息融入到了后来提到的分类模型中。在前几名的答辩中,都是同时使用了这两个特征,分别或者一起放到深度学习框架里进行训练。然后和正常的TFIDF特征一起进行集成学习。这点是我们差距很大的地方。
同时在后来和高君老师的聊天中,他也提到了目前搜狗的做法也是利用词向量特征直接放到深度学习框架中来做。不同的是,他们拥有着十分庞大的数据量,所以效果更加显著。
2.2 分类模型
我们在比赛中最后使用的集成模型是stacking模型。这里详细介绍一下这个模型,算是对队友的一个补充。
经典Stacking模型是指将多种分类器组合在一起来取得更好表现的一种集成学习模型。一般情况下,Stacking模型分为两层。第一层中我们训练多个不同的模型,然后再以第一层训练的各个模型的输出作为输入来训练第二层的模型,以得到一个最终的输出。为了更加详细的阐述stacking模型的训练和预测过程,我们用下面的图作为示例。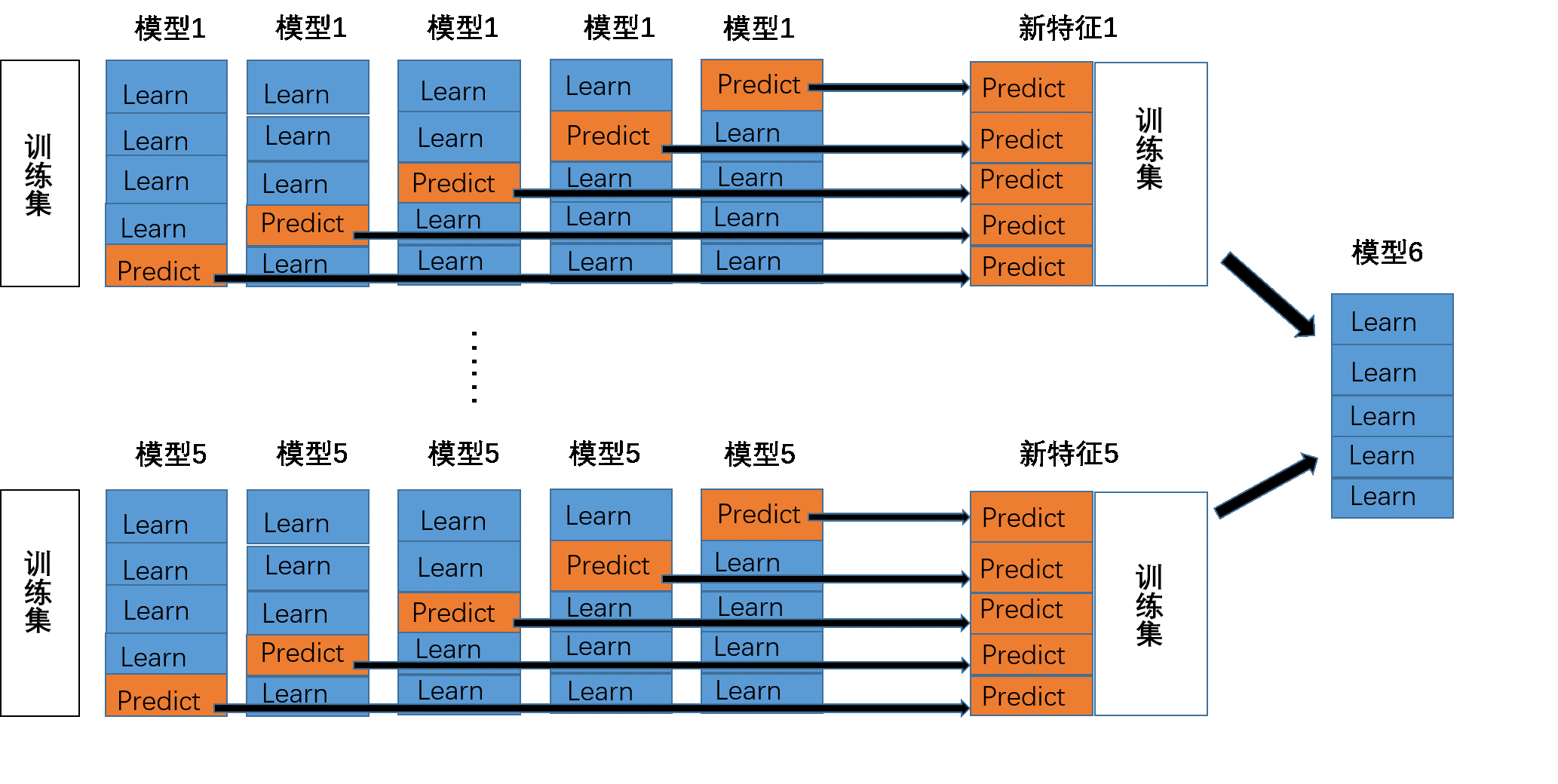
首先,我们从stacking模型的训练开始阐述。在上图中我们可以看到,该模型的第一层有五个分类模型,第二层有一个分类模型。在第一层中,对于不同的分类模型,我们分别将训练数据分为 5 份,接下来迭代5次。每次迭代时,将 4 份数据作为训练集对每个分类模型进行训练,然后剩下一份数据在训练好的分类模型上进行预测并且保留结果。当5次迭代都完成以后,我们就获得了一个结果矩阵。该矩阵是一个N1的矩阵,N是训练集的样本数。当5个模型都进行完上述操作后,我们就可以得到一个N5的结果矩阵。然后将该矩阵导入到第二层的模型6中进行训练,此时全部模型训练完毕。接下来是stacking模型的预测过程。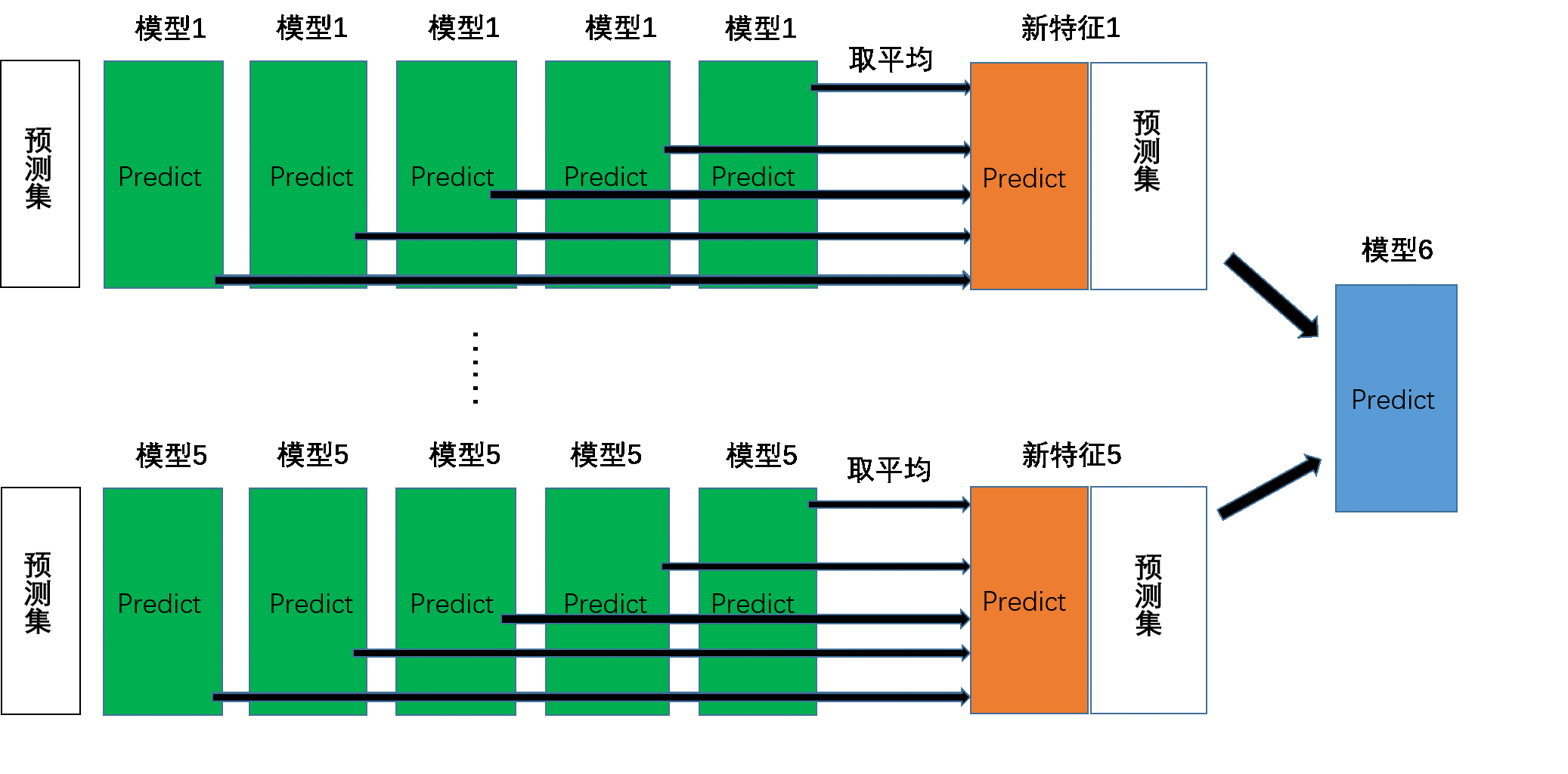
接下来我们开始阐述该模型的预测过程。在第一层中,对于不同分类模型,我们还是使用在训练时分成的5份训练数据进行五次迭代。每次迭代时,我们利用训练后的分类模型对预测集进行预测并保留下来。当5次迭代都完成以后,我们可以得到一个M5的矩阵,M是预测集的样本数。 我们将这个矩阵按列取平均,缩减成M1的矩阵。当5个模型都进行完上述操作后,我们就可以得到一个M*5的结果矩阵。然后将该矩阵导入到第二层中训练好的模型6进行预测,就可以得到最终的预测结果。
在介绍完经典stacking模型的训练及预测过程后,接下来阐述我们自己的stacking模型构建和改进。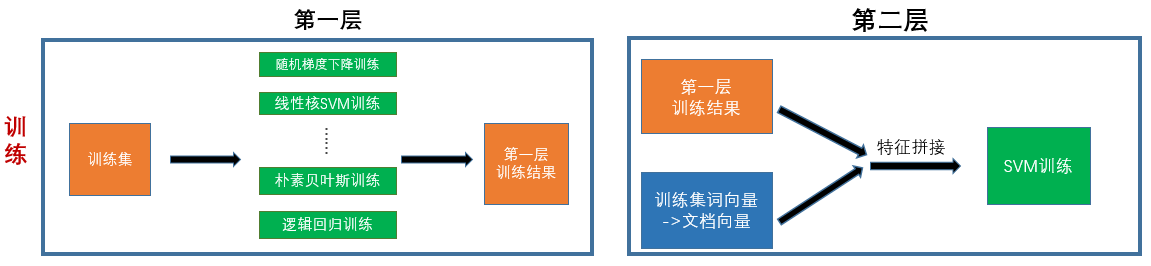
在模型训练过程中,模型第一层中的分类模型有25个。这其中包含了不同类型的分类器,和同一类型但是参数不同的分类器。增加这些分类器的原因是为了增加训练扰动,能够缓解分类模型的过拟合问题。在第二层中,我们使用了SVM分类器。同时我们加入了由词向量转变而成的文档向量矩阵,与第一层的训练结果进行特征拼接,拼接后的结果用来进行训练。加入词向量特征,可以引入词向量所含的语义信息。之所以加在第二层是因为第一层训练集特征的稀疏特性不适合与具有密集特性的词向量进行融合。
在预测过程中,流程和训练过程相似,只是改成了用预测集在训练好的分类模型上进行预测。我们注意到,在Stacking模型中,由于在第一层的预测过程也需要使用第一层时的数据划分,所以一般Stacking模型的运行顺序是:
- 第一层训练
- 第一层预测
- 第二层训练
- 第二层预测
至此,我们改进后的stacking模型介绍完毕。
下面谈一下自己使用过程中的感受吧。
- 在sklearn中也是有集成模型的。但是他只有boosting和bagging的集成模型代码。可能还是因为stacking模型的灵活性太高了吧。
- 我们在第一层的模型选择上,主要是考虑到了速度问题,所以选取的都是一些线性分类器和速度比较快的线性核svm等。第二层我们使用的是rbf核SVM。但是在第二层的特征数由于加入了词向量特征而变大后,第二层的训练预测时间变得很长。所以SVM好,但是使用需谨慎啊。
- 对于xgboost模型,我们在和svm比较后,发现比不过svm分类器。同时xgboost的调参也是一个蛮长的贪心过程。所以我们没有使用xgboost。但是在答辩中,前几名的大神在集成模型上几乎都用到了xgboost。这也说明xgboost的效果还是非常好的。
- stacking模型理论上可以扩大到无数层。但是在答辩过程中,发现大家都是只使用了两层,同时我们也实验了搭出三层的stacking,效果也不如两层的。
- 在一开始的时候,我们只在第一层中放入了四个分类器,但是受到了一些博客的影响,我们开始尝试加入更多的分类器。第一种是不同类型的分类器,但是更多的是同类型,但是不同参数下的分类器。我们发现,分类器越多时,最终效果更好。但是随着分类器的增多,效果提升的越来越少。但是这不失为是一个刷分的好方法。
3. 赛后总结
- 在比赛过程中,我们发现,想做到前50,就去多看大神博客。但是想做到前5,还是需要阅读一些这方面的论文进行思想上面的补充的。
- 由于我们做的是文本方面的问题,还有看到了一些图像方面的问题。深度学习都已经是主流的解决方法。但是我们也看到在一些传统的以特征工程为主的问题解决中,还是有不少都是利用传统的数据挖掘算法进行解决的。所以不能盲目迷信深度学习,也是要分情况讨论的。
- 不管在什么问题上,对于数据的分析都是十分重要的。这也是评委老师们十分看重的一点。毕竟大家的整体模型不会有很大差距,差距的所在很多情况下都是在对数据的分析上。
- 如果你是一个比赛小白,还是需要找一个靠谱的团队,不论是从哪个方面都能帮助你很多。当然也是有很多solo大神,这里只能膜拜了。
- 一个小建议:如果你答辩紧张,可以事先背演讲稿O(∩_∩)O哈哈~,亲测有用。
4. 代码
代码和答辩PPT已经公开 传送门。在coding的过程中,也阅读了一些源码,发现自己的代码写的还是比较low的。在接下来有时间我准备把分类模型stacking这块的代码重构一下,尽量能够达到可复用的目标吧。
这里给大家一些自己的看法:
- 尽量能让自己的代码达到模块化,不管在后期修改和阅读中都有很大好处。在这里我们吃了很大的亏。
- 多阅读一些比较著名的源码。真的会对我们有很大帮助。
python数据挖掘包集合总结:
- 基础包:numpy,scipy
- 大神级数据挖掘包:sklearn
- 数据可视化:pandas
- 数据不均衡:imbalanced-learn
- 大神级nlp包:gensim(word2vec和LDA)
- 深度学习包:TensorFlow


